


8. RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval
AI Paper By Hand

Last week I covered papers on Vision-Language-Action(VLA) models and that made me think more extensively about how foundational attention is and how important longer context can become with respect to it (and that context may grow exponentially).
However, attention computation is quadratic in complexity and so scaling LLMs to longer contexts is non-trivial. It can incur extremely slow inference latency and high GPU memory consumption for caching those very important key-value (KV) vectors.
Many ideas have been coming up to address this issue, but this one called 'RetrievalAttention' by Microsoft caught my eye. Reason being it accelerates attention computation and reduces GPU memory consumption, but does all these while being training-free.
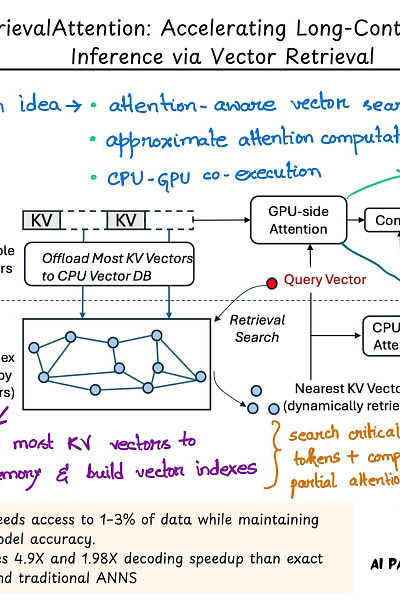
RetrievalAttention works by designing an attention-aware vector search algorithm that can adapt to the distribution of query vectors. According to the paper, it only needs to access 1–3% of data while maintaining high model accuracy.
Retrieval Attention has four key ideas:
1. It makes use of dynamic sparse attention during token generation, allowing the most critical tokens to emerge from the extensive context data.
2. It focuses on the distribution of queries rather than key similarities.
3. It divides KV vectors efficiently between GPU and CPU: vectors that follow static patterns remain in the GPU (smaller in number), while the rest are offloaded to CPU for index construction.
4. It efficiently retrieves critical tokens using vector indexes on the CPU and merges the partial attention results from both CPU and GPU, thus reducing latency and memory footprint.
From the paper:
"We evaluate the accuracy and efficiency of RetrievalAttention on both commodity GPUs (4090) and high-end GPUs (A100) on three long-context LLMs across various long-context benchmarks. For the 128K context on the 4090 GPU, RetrievalAttention achieves 4.9× and 1.98× decoding-latency reduction compared to the retrieval method based on exact KNN and traditional ANNS indexing respectively, while maintaining the same accuracy as full attention. To the best of our knowledge, RetrievalAttention is the first solution that supports running 8B-level models on a single 4090 GPU (24GB) with acceptable latency and almost no accuracy degradation."
Paper : https://arxiv.org/abs/2409.10516