


6. RT-1: Robotics Transformer for Real-World Control at Scale
AI Paper By Hand

As I was reading the OpenVLA paper, I saw a lot of references to the RT-2 model (a 55B model that is outdone by OpenVLA by 16.9%). So, I had to learn what RT-2 was which consequently led me to the original model that it is based on : RT-1.
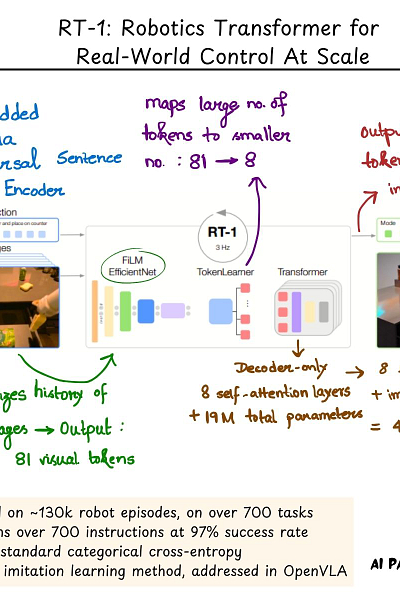
RT-1 which stands for Robot Transformer 1 encodes high-dimensional inputs and outputs into token representations that gets processed by a transformer backbone ultimately enabling real-time control.
The RT-1 architecture looks something like this:
1. First, it is based on compact tokenization of images and language instruction. For images, it uses the EfficientNet (https://arxiv.org/pdf/1905.11946) model that outputs a outputs a spatial feature map. This feature map is flattened into 81 visual tokens. FiLM (https://arxiv.org/pdf/1709.07871) layers are added to the pretrained EfficientNet to condition the image encoder.
2. To speed-up inference, these 81 tokens pass through a TokenLearner which further reduces the number of tokens to 8.
3. Finally, these 8 tokens are taken per-image and combined with a history of images adding up to 48 tokens which act as input to the transformer. The transformer used here is a decoder-only model with 8 self-attention layers and 19M parameters in total. Theis outputs the action tokens. A standard categorical cross-entropy loss is used.
RT-1 was trained on ~130k robot episodes based on over 700 tasks over the course of 17 months with 13 robots.. It can perform 700 instructions at 97% success rate and effectively generalizes to new tasks. However, as per the paper its limitation lies in the fact that it follows an imitation learning method - which means it can only do so well as its demonstrators. Also, it can generalize to new tasks but only if they are combinations of previously seen concepts.
And hence the efforts towards making RT-2 and now the launch of OpenVLA. But RT-1 did enable a spearhead effort for working with open-ended task-agnostic training, coupled with high-capacity architectures that can work with a diverse range of robotic data.
Paper : https://arxiv.org/abs/2212.06817