


5. OpenVLA: An Open-Source Vision-Language-Action Mode
AI Paper By Hand

Multimodal LLMs have seen a huge surge recently with numerous efforts driving this endeavor in the field of AI. Multimodal LLMs refer to large language models that work with different modes of inputs.
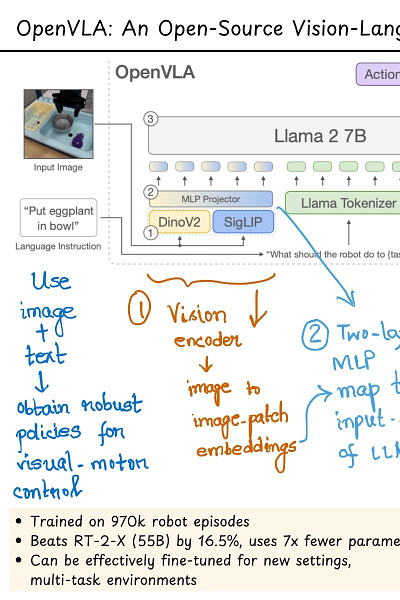
Talking about multimodal LLMs, I recently came across this paper about Open-Source Visual-Language-Action (OpenVLA) model which looks very exciting! It not only combines visual and texts as inputs but uses those to predicts robotic actions. The way OpenVLA does it can be summarized into four main steps:
1. It first uses a Vision Language model (VLM) called Prismatic-7B that is based on two visual encoders : pre-trained DinoV2 and SigLIP. The VLMs map input images to input patch embeddings.
2. These embeddings then pass through a 2-layer MLP that projects the input patch embeddings to input dimensions that correspond to the LLM's input space.
3. The LLM used by OpenVLA is the Llama2 model which then maps the inputs to a string of predicted robot actions. (The 'how' can be an entirely different write-up.)
4. Finally, the action tokens produced by Llama2 are used for training with an objective of next-token prediction (by evaluating the cross-entropy loss on the predicted action tokens).
OpenVLA(7B) is trained on 970k diverse real-world robotic episodes and when compared to closed models like RT-2-X(a 55B model) which has 7x more parameters, OpenVLA shows a 16.9% success rate over it. It also shows strong generalization results in multi-task environments involving multiple objects and strong language grounding abilities.
Big thing is OpenVLA is open-source with all all models, deployment and fine-tuning notebooks, and the OpenVLA codebase for training VLAs, all of which are available here: https://lnkd.in/gzBxf5XK
Definitely a great step in the field of VLAs!
Paper : https://arxiv.org/abs/2406.09246