


4. THINKING LLMs: General Instruction Following with Thought Generation
AI Paper By Hand

Read another interesting paper 📜 the other day - 'THINKING LLMS: General Instruction Following with Thought Generation'. I was intrigued to learn how to make the LLMs wear the thinking cap? 🧢
Well, Chain-of-Thought (CoT) has been quite popular recently with its idea of asking the model to write down reasoning steps. However, it has mostly been limited to math and reasoning tasks (which I think is quite wonderful in its place).
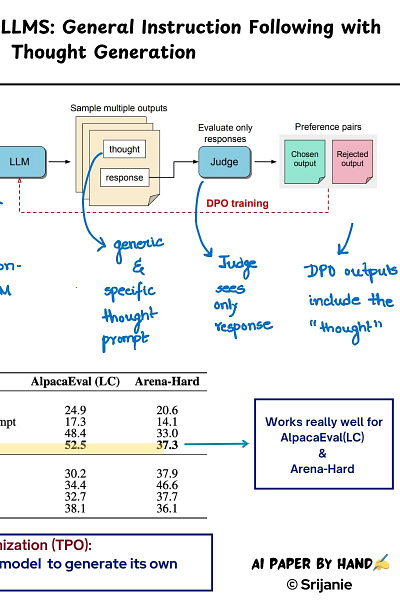
Thinking LLMs, on the other hand, focus on general instruction tasks. How do they do it? By using Thought Preference Optimization or TPO - TPO trains a instruction-tuned LLM further to have its own 'thoughts'. It does so by:
1. Asking the model to generate sequence of outputs which is divided into thoughts and response parts.
2. The thought and response outputs are optimized through Reinforcement Learning from AI Feedback (RLAIF).
3. A judge model is then asked to evaluate the responses only (it does not see the thought, neither does the user).
4. Based on the preferred and rejected outputs, pairs are formed which are then subsequently used for DPO optimization.
Results on the Llama3-8B-Instruct model shows that TPO works quite well with a win rate of 52.5% and 37.3% respectively for the AlpacaEval and Arena-Hard benchmarks. Other models too show quite a promise.
Way to go LLMs!
Paper : https://arxiv.org/pdf/2410.10630