


12. Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models
AI Paper By Hand

With multimodal models on the rise, Meta recently introduced a sparse multi-modal transformer architecture called 'Mixture-of-Transformers (MoT)' that has a huge impact on reduction of pre-training computational costs.
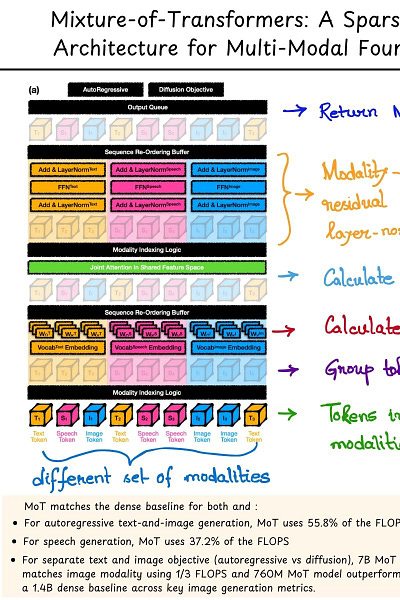
This new architecture focuses on splitting the model by modality for embedding, calculation of attention matrices, feed-forward networks (FFNs) and layer normalization while calculating a global self-attention for the entire input sequence across different modalities.
The steps can be summarized as:
1. Create token indices for different modalities.
2. Group those tokens by modality.
3. Calculate the attention projections.
4. Calculate global self-attention in shared feature-space.
5. Calculate modality specific FFNs, residual connections and layer-normalization.
6. Collect them all to give out the final outputs.
Based on the paper, the results are quite promising:
"- For autoregressive text-and-image generation, MoT matches the dense baseline’s performance using only 55.8% of the FLOPs.
- When extended to include speech, MoT reaches speech performance comparable to the dense baseline with only 37.2% of the FLOPs.
- In the Transfusion setting, where text and image are trained with different objectives, a 7B MoT model matches the image modality performance of the dense baseline with one third of the FLOPs, and a 760M MoT model outperforms a 1.4B dense baseline across key image generation metrics.
- System profiling further highlights MoT’s practical benefits, achieving dense baseline image quality in 47.2% of the wall-clock time and text quality in 75.6% of the wall-clock time (measured on AWS p4de.24xlarge instances with NVIDIA A100 GPUs)."
Must say it's a very interesting approach 👏 !
Paper : https://arxiv.org/pdf/2411.04996