


11. On the Surprising Effectiveness of Attention Transfer for Vision Transformers
AI Paper By Hand

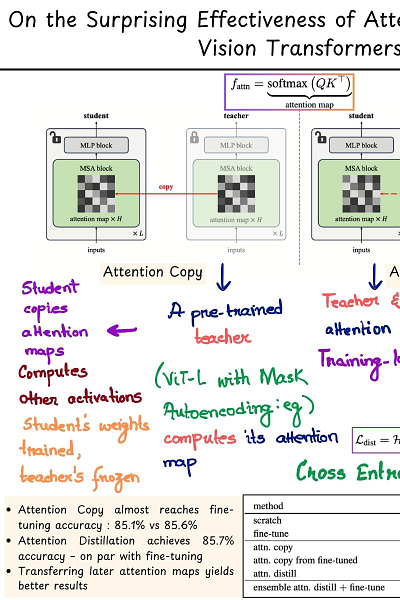
This paper illustrates how using only the attention patterns (information flow between tokens) from pre-training is sufficient for models to learn high quality features from scratch. The method demonstrated is called attention transfer.
Attention transfer occurs from a teacher model to a student in two ways:
1. By Attention Copy : “Copy-and-paste” the attention maps from a pre-trained teacher model to a randomly initialized student one.
2. By Attention Distillation : The student computes its own attention maps along with the teacher, and an additional cross-entropy loss is used to distill patterns from the teacher during training.
Attention map here represents the softmax of the product of Q and K matrices - 𝘀𝗼𝗳𝘁𝗺𝗮𝘅(𝗤.𝗞^𝗧). As is well known, attention maps determine how the values from other tokens are aggregated.
The paper calls out two main observations:
1. Attention Copy almost reaches fine-tuning accuracy : 85.1% for Attention Copy vs 85.6% (fine-tuning).
2. Attention Distillation achieves 85.7% accuracy which is on par with fine-tuning.
The analysis is based upon a ViT-L pre-trained model with Masked Autoencoding (more on this later) for ImageNet-1K classification.
The key finding being "attention patterns (inter-token operations) are the key factor behind much of the effectiveness of pre-training".
Quite interesting!
Paper : https://arxiv.org/abs/2411.09702