


1. What Matters in Transformers? Not All Attention is Needed
AI Paper By Hand

The tale of transformers is based on the groundbreaking attention mechanism. However, a new paper "What Matters in Transformers? Not All Attention is Needed" (Shwai He, Guoheng Sun, Zheyu Shen, Ang Li, 2024)
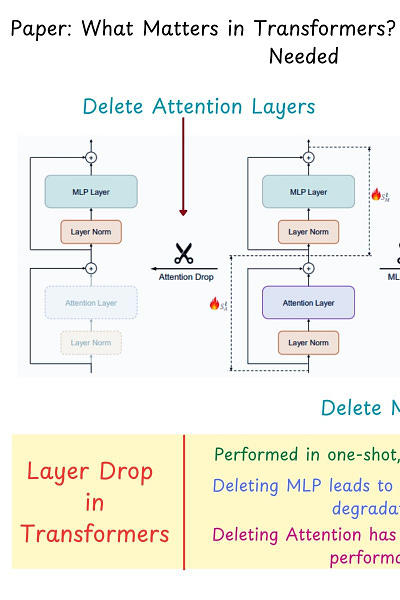
suggests that removing a big portion of these attention layers from the model does not affect its performance. The reason being these layers exhibit high (cosine) similarity and thus appear redundant.
Interestingly, both Llama-2-13B and Mistral-7B maintain over 99% of their original performance even after dropping 8 attention layers. Also, Llama-2-70B achieved a 48.4% speedup with only a 2.4% performance drop by deleting half of the attention layers. This could mean a huge deal for model compression.
However, for now the paper only covers certain benchmarks (HellaSwag, MMLU, etc.) - it would be interesting to see how this technique fares as more benchmarks are included. Looks promising!
Paper : https://arxiv.org/pdf/2406.15786